Overview
For this assignment, you will create a program that can read and write text expressed using a variable bitrate encoding. Such schemes can be used to compress files so that both storage and transmission consume fewer resources.
The canonical variable bitrate algorithm is called Huffman coding after its inventor, David Huffman, who came up with the technique and proved its optimality while still a student, in response to a homework assignment from his professor. You can read more about the algorithm in its Wikipedia article. Basically, more common characters are encoded using short bit strings, while rarer characters use much longer bit strings. The savings on the short, common characters more than makes up for the extra bits used for the rarely occurring longer characters.
To avoid confusion, Huffman coding uses a prefix code scheme, meaning that no character's encoding forms the beginning sequence of any other. So for example, if the code 00 represents the letter e, then no other code may begin with 00 -- they must all use 01, 10, or 11 instead. This ensures that the encoded bit string has a unique interpretation. It also means that the encoding scheme can be conveniently represented using a binary tree, with symbols at the leaves, and the corresponding code for that symbol determined by the path to it from the root. By convention, left branches correspond to a 0 in the code, and right branches to a 1. So if the leaf node for the letter t is reached by going left-right-left from the root, then the code for t would be 010.
To Do
The core of this assignment is a HuffTree class that will represent a prefix code. Write this class first, trying to make it as generally useful as possible. It is best if you can make this a subclass of BinaryTree<Character>, so that you inherit all the methods we defined there. But you can also make it a separate class on its own, and this may be a little bit easier conceptually. Either way it will be a pure data class -- there is no main method -- yet!
Once you have finished HuffTree, you will write up to three short programs using this class to perform various related tasks. Each of these will have its own main method and can be run independently. They are described in the sections below.
Only the first two need to be completed for the standard assignment. The third (building a Huffman tree from frequency counts) is optional for extra credit.
Huffman Decoding
The first program, HuffDecode, will read a code from a file and build a Huffman tree from it (more on this below). It will then use the tree to convert a file from code into plaintext. The method you write to do this may be either recursive or iterative. The command to run the program will look as follows:
java HuffDecode codeFile < encoded.txt > decoded.txt
(You may wish to review the tutorial on file redirection to understand what is happening here. Basically, the file encoded.txt is being sent to your program as System.in, and the output your program writes to System.out gets stored in decoded.txt. All this is done by the operating system as a result of the command above, without the need for your program to specify it.)
To implement the decoding, your program will need to travel down the tree as it travels past the input bits. Each time it reaches a leaf in the tree, it emits the character stored at the leaf, and then returns to the root.
When your program is running correctly, you can use this code file to decode this encoded text. What is the secret message? Show the answer in your typescript.
Huffman Encoding
The second program, HuffEncode, is perhaps the simplest, and doesn't even need a tree. It will read a code file and then convert plaintext to encoded text. You can do this with a simple lookup table -- at the index of the character to be encoded, you will store the corresponding code. The command to run the program will look as follows:
java HuffEncode codeFile < original.txt > encoded.txt
If you have written the two programs above correctly, you should be able to pipe them together as shown below:
java HuffEncode codeFile < original.txt | java HuffDecode codeFile > decoded.txt
In the example above, decoded.txt should come out identical to original.txt.
Reading a Tree File
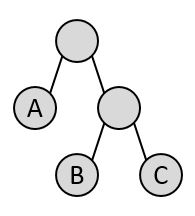
Your program should be able to read (and write, if you do the extra credit below) a simple text file storing the tree data and its structure. The file format a code is very simple. Each line will consist of a bit pattern (the code) in zeros and ones, followed by a number between 0 and 255 representing the ASCII value of the character it corresponds to. You should interpret the bit pattern as a path to a particular node in a tree (0 = left, 1 = right), and the character as the value to be stored at the node. Here's a mini-example, representing the tree shown at right:
0 65 10 66 11 67
When reading in the code, build the tree by traveling down it left or right according to the bit pattern, creating new nodes as necessary while you go. (You may fill these intermediate nodes with null characters, '\0'.) When you get to the end of the pattern, you should be at a new leaf node. Store the character value in the data field of that node. Note: If you read the value as an int v, you can cast it to type char as follows: (char)v.
Extra Credit: Building a Tree From Data
The third program (optional) will read a plaintext file, count the frequencies of the characters that occur, and use them to build a tree according to Huffman's algorithm. It will then output a code file of the sort used by the two programs above.
java BuildHuffTree codeFile < sampleText
When you have completed this portion, you should also carry out the analysis experiment described in the section below.
Your encoding scheme should be able to encode any 8-bit ASCII character. When processing the text file to build the tree, keep a count of the number of appearances of every character code from 0 to 255. You will use these counts to build the tree. Ignore any characters with values greater than 255.
Notes
For simplicity, the encoded files will record each bit as a character '0' or '1', which is actually represented in ASCII code using 8 bits! This makes the encoded files easy to read in a text editor. However, it does not decrease the file size since we are using 8 times the number of bits that are actually needed. We will overlook this small problem in favor of the convenience of a human-readble output. If you really wanted to use a Huffman encoding to save space, you would have to manipulate individual bits and read and write the encoded data as a binary file, but that's not necessary for the main assignment. (See extra credit below.)
Extra Credit -- Analysis
How much difference does the specific encoding tree make in the compression rate? You can explore this question for extra credit. Consider three files: a short test message ("This is a test of Huffman coding."), the system dictionary file (at /usr/share/dict/words on aurora), and Tolstoy's War and Peace. (Note: if you are working on aurora, please used the copy stored at ~212a/handout/war_and_peace.txt rather than making your own copy.)
Use each file as the source text to build a tree. Then encode each file using each tree. Make a table of the compression rates (bits/character) in your README. For each document, which code has the best compression rate? Which source's code offers the best average compression rate over all three documents? Explain these observations. Are there any other interesting patterns? What do you conclude?
Additional Extra Credit -- Bit Encoding
As further extra credit, you may make a new program, modified from the original, that reads and writes binary coded files. These should be 1/8 the size of the files written using ASCII digits. A file that is encoded and decoded using your programs should be exactly identical to the original. Only attempt this one if you have already completed all three programs above, plus the first extra credit.
To Submit
- HuffTree.java
- HuffEncode.java to encode files
- HuffDecode.java to decode files
- BuildHuffTree.java to create a tree
- readme.txt
- typescript, showing your programs in action for a short test file
- For second extra credit: HuffBitEncode.java and HuffBitDecode.java